Variational Inference
Model Comparison
Clustering
Autoregressive Models
Planning as Inference
State Space Models
Artificial Neural Networks
Independent Component Analysis
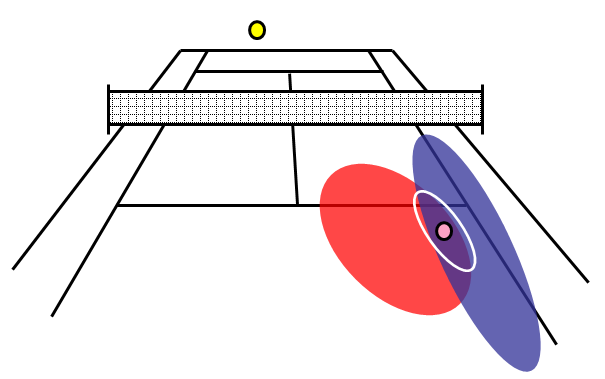
The ideas behind Bayesian inference can be illustrated using the game of tennis.
In this example the best estimate of where a tennis ball will land is made by combining
information about where the opponent served before (the prior) with information from the visual system about
the current trajectory of the ball (the likelihood).
The prior is shown in blue, the likelihood distribution in red, and
the posterior distribution with the white ellipse. The maximum
posterior estimate is shown by the magenta ball. This estimate can
be updated in light of new information from the balls trajectory.
W.D. Penny and K. J. Friston.
Bayesian Treatments of Neuroimaging Data.
In K. Doya and I. Naguno, editors, The Bayesian Brain.
2006.
 Keyword(s): fMRI,
Dynamic.
[bibtex-entry] Keyword(s): fMRI,
Dynamic.
[bibtex-entry]
W. Penny (2012).
Bayesian models of Brain and Behaviour.
ISRN Biomathematics Volume 2012, Article ID 785791, doi:10.5402/2012/785791
Exact Bayesian inference is not possible for nonlinear models. Instead, one must use approximate inference frameworks, and Variational Inference is one such approach. It factorises the posterior density and optimises the parameters of the factors so as to minimise the KL divergence between the true and approximate posterior. It also provides a lower bound on the the model evidence. This bound is the "negative free energy".
Inference using Variational Bayes PDF , Workshop on the Free Energy Principle, July 5th 2012.
W. Penny,
S. Kiebel,
and K. Friston.
Variational Bayes.
In K. Friston,
J. Ashburner,
S. Kiebel,
T. Nichols,
and W. Penny, editors, Statistical Parametric Mapping: The analysis of functional brain images.
Elsevier, London,
2006.
Keyword(s): Variational,
Bayesian.
[bibtex-entry]
K.Friston,
J. Mattout,
N. Trujillo-Barreto,
J. Ashburner,
and W. Penny.
Variational free energy and the Laplace approximation.
Neuroimage,
34(1):220-234,
2007.
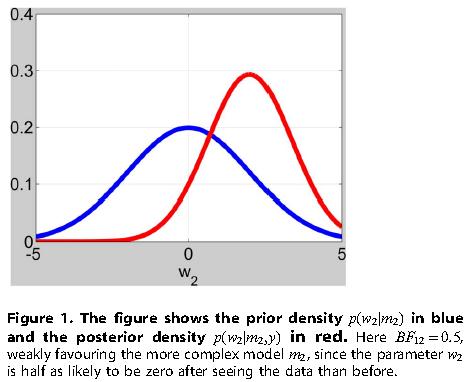
Model comparison is crucial to the scientific endeavour. How is it we decide that one scientific model is better than another ? Which model has the strongest empirical support ? Bayesian inference in this context allows us to optimally update our beliefs about which are the best models in light of new experimental evidence. This is a continually evolving process. A key quantity here is the evidence for each model, but this can be difficult to compute especially for eg. nonlinear models. One of our recent approaches is to approximate the evidence using a Savage-Dickey method - we decide if model parameters are necessary by looking at how probable they are to be zero a-posteriori versus a-priori.
W. Penny,
J. Mattout,
and N. Trujillo-Barreto.
Bayesian model selection and averaging.
In K. Friston,
J. Ashburner,
S. Kiebel,
T. Nichols,
and W. Penny, editors, Statistical Parametric Mapping: The analysis of functional brain images.
Elsevier, London,
2006.
Keyword(s): Bayesian,
BMC,
EEG.
[bibtex-entry]
W. Penny and G. Ridgway (2013).
Efficient Posterior Probability Mapping using Savage-Dickey Ratios.
PLoS One 8(3), e59655
W. Penny (2011).
Comparing Dynamic Causal Models using AIC, BIC and Free Energy.
Neuroimage Available online 27 July 2011.
Friston K, Penny W. (2011)
Post hoc Bayesian model selection.
Neuroimage. 56(4), 2089-2099.
W Penny, K Stephan, J. Daunizeau, M. Rosa, K. Frsiton, T. Schofield and
A Leff.
Comparing Families of Dynamic Causal Models.
PLoS Computational Biology,
Mar 2010, 6(3), e1000709.
W.D. Penny,
K.E. Stephan,
A. Mechelli,
and K.J. Friston.
Comparing Dynamic Causal Models.
NeuroImage,
22(3):1157-1172,
2004.
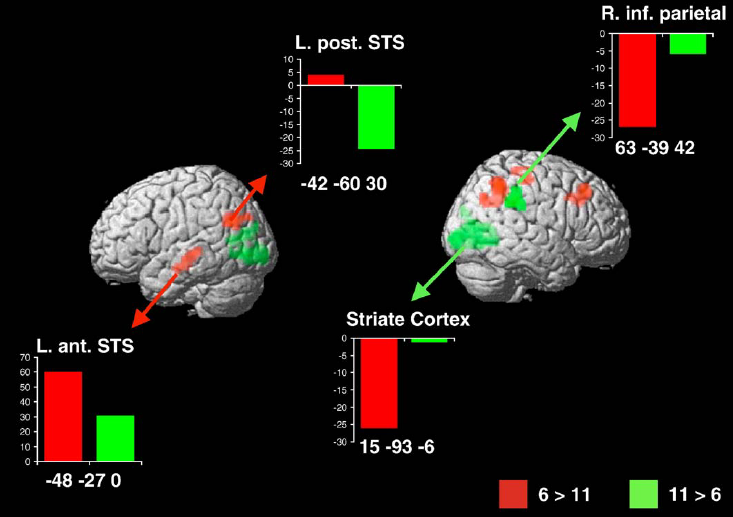
We can estimate the number of clusters in a data set using Bayesian inference applied to mixture models eg. the figure below shows two neural systems (two clusters of responsive voxels, one shown in red, the other in green) underlying the pattern of brain activations measured in a multiple subject fMRI study (6 subjects in the red cluster, 11 in the green). These are subjects performing exactly the same task, but using different parts of the brain.
S. J. Roberts,
D. Husmeier,
W. Penny,
and I. Rezek.
Bayesian Approaches to Gaussian Mixture Modelling.
IEEE Transactions on Pattern Analysis and Machine Intelligence,
20(11):1133-1142,
1998.

W.D. Penny.
Variational Bayes for d-dimensional Gaussian mixture models.
Technical report,
Wellcome Department of Cognitive Neurology, University College London,
2001.
Keyword(s): Variational,
Mixture.
[bibtex-entry]
U. Noppeney,
W. D. Penny,
C. J. Price,
G. Flandin,
and K. J. Friston.
Identification of degenerate neuronal systems based on intersubject variability.
Neuroimage,
30:885-890,
2006.
K. Brodersen, L. Deserno, F. Schlagenhauf, Z. Lin, W. Penny, J. Buhmann and K. Stephan (2014).
Dissecting psychiatric spectrum disorders by generative embedding.
Neuroimage: Clinical, 4, 98-111 ,
Linear Autoregressive models predict eg. the future value of a time series using a weighted combination of previous values of the time series. Their multivariate equivalents also use previous values of other time series as predictors. Usefully, one can transform the parameters to make a parametric estimate of eg. the power spectral density matrix (power, coherence etc).
 L. Harrison,
W.D. Penny,
and K.J. Friston.
Multivariate Autoregressive Modelling of fMRI time series.
NeuroImage,
19(4):1477-1491,
2003.
L. Harrison,
W.D. Penny,
and K.J. Friston.
Multivariate Autoregressive Modelling of fMRI time series.
NeuroImage,
19(4):1477-1491,
2003.
M.J. Cassidy and W.Penny.
Bayesian nonstationary autogregressive models for biomedical signal analysis.
IEEE Transactions on Biomedical Engineering,
49(10):1142-1152,
2002.
W.D. Penny and S.J. Roberts.
Bayesian Multivariate Autoregresive Models with structured priors.
IEE Proceedings on Vision, Image and Signal Processing,
149(1):33-41,
2002.
S.J. Roberts and W.D. Penny.
Variational Bayes for Generalised Autoregressive models.
IEEE Transactions on Signal Processing,
50(9):2245-2257,
2002.
W. Penny, P. Zeidman and N. Burgess (2013).
Forward and backward inference in spatial cognition.
PLoS Computational Biology, 9(12) e1003383 ,
W. Penny (2014).
Simultaneous Localisation and Planning.
4th International Workshop on Cognitive Information Processing, Copenhagen, Denmark.
W.D. Penny and S.J. Roberts.
Dynamic models for nonstationary signal segmentation.
Computers and Biomedical Research,
32(6):483-502,
1999.
W.D. Penny,
Z. Ghahramani,
and K.J. Friston.
Bilinear Dynamical Systems.
Phil Trans R Soc B,
360(1457):983-993,
2005.

The Multilayer Perceptron is a classic Artificial Neural Network that was popular in the 1990s. It uses a layer of hidden units each of which bipartitions 'input space' into distinct regions (see straight lines in Figure below). An output layer, comprising a sigmoidal function, can then combine these partitions into an arbitrarily complex response function (see dark versus light regions below). The number of hidden units can be selected using Bayesian model comparison.
 D. Husmeier,
W.D. Penny,
and S.J. Roberts.
An empirical evaluation of Bayesian sampling with hybrid Monte Carlo for training neural network classifiers.
Neural Networks,
12:677-705,
1999.
D. Husmeier,
W.D. Penny,
and S.J. Roberts.
An empirical evaluation of Bayesian sampling with hybrid Monte Carlo for training neural network classifiers.
Neural Networks,
12:677-705,
1999.
W.D. Penny and S.J. Roberts.
Bayesian neural networks for classification: how useful is the evidence framework ?
Neural Networks,
12:877-892,
1998.
D. Husmeier W.D. Penny and S.J. Roberts.
The Bayesian Paradigm: second generation neural computing.
In P. Lisboa, editor, Artificial Neural Networks in Biomedicine.
Springer-Verlag,
1999.
Keyword(s): ANN.
[bibtex-entry]
S.J. Roberts W.D. Penny and R. Everson.
ICA: Model-order selection and dynamic source models.
In S.J. Roberts and R. Everson, editors, ICA: Principles and Practice,
pages 299-314.
Cambridge University Press,
2000.
Keyword(s): Variational,
ICA,
Mixture.
[bibtex-entry]
R. Everson W.D. Penny and S.J. Roberts.
Hidden Markov Independent Component Analysis.
In M. Giroliami, editor, Advances in Independent Component Analysis.
Springer,
2000.
Keyword(s): Markov,
ICA,
Dynamic.
[bibtex-entry]
|